강화학습이란?
강화학습의 목표는 환경(environment)과 상호작용하는 임의의 에이전트(agent)를 학습시키는 것입니다. 에이전트는 환경 속에서 상태(state)를 인식하여 행동(action)하며 학습해 나갑니다. 에이전트가 취한 행동의 응답으로 환경은 양수 혹은 음수 또는 0을 보상(Reward)으로 돌려줍니다.

에이전트의 목표는 초기 상태부터 종료 상태까지 받을 수 있는 보상을 최대화하는 것입니다. 따라서 에이전트가 좋은 행동을 했을 때는 큰 보상을 주어 그 행동을 강화하고 그렇지 않은 행동을 했을 때는 작은 보상 혹은 음의 보상을 줍니다.
Q 러닝?
Q 러닝은 강화학습 기법 가운데 하나입니다. Q 러닝은 지금은 너무나도 유명한 알파고가 나오기 전부터 존재했던 알고리즘입니다. 여러 가지 한계점으로 인해 사용되지 않고 있었는데, Q 러닝이 인공지능과 만나면서 엄청난 성능을 보이며 유명세를 탔습니다. 그 알고리즘이 바로 구글 딥마인드에서 개발한 DQN (Deep Q-network)입니다. DQN을 이해하기 위해서라도 Q 러닝이 무엇이고 어떻게 학습되는지 알아두면 좋습니다.
Frozen Lake
Q 러닝에 대한 설명을 위해 문제를 하나 가정하려 합니다. 여기선 문제이자 곧 환경이라 할 수 있겠네요. Frozen lake 문제는 빙판 위의 에이전트가 시작 지점에서 출발하여 목적지까지 도착해야 하는 문제입니다. 빙판 곳곳에는 구멍이 있어 구멍을 피해 목적지에 도착해야 합니다.

예를 들어, 위 그림과 같은 Frozen Lake 문제가 주어졌다고 해보죠. 이때, S는 시작 지점, F는 일반 빙판 길, G가 목표지점 그리고 H가 구멍입니다. 이 경우는 아래 그림처럼 구멍을 피해 목적지에 도달하면 됩니다.
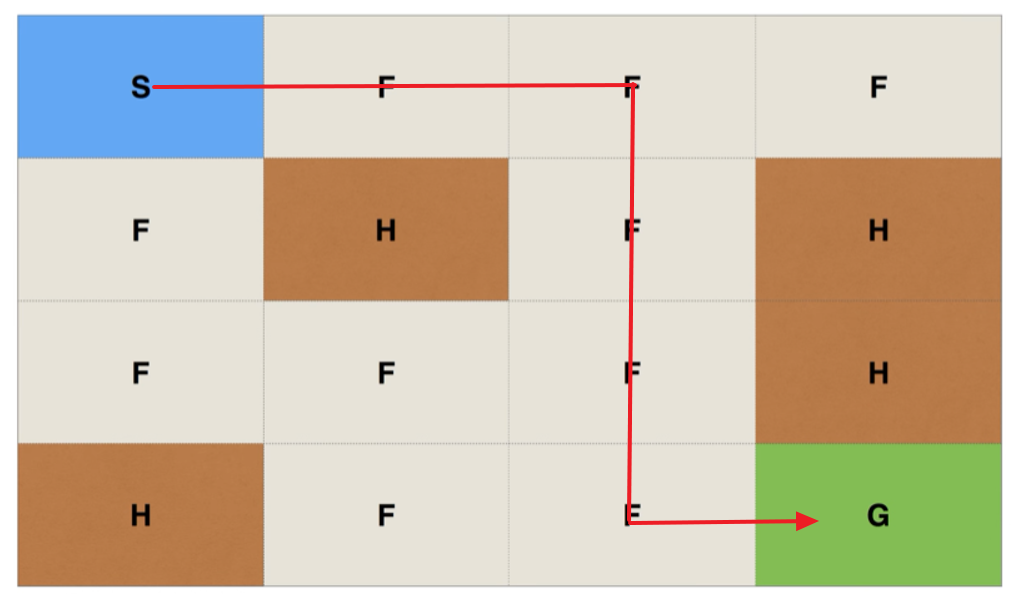
전체 문제를 볼 수 있는 입장에서는 문제가 쉬워 보이지만 에이전트는 전체 판을 볼 수 없고 현재 상태만 알 수 있다는 것에 주의하셔야 합니다. 또한, 에이전트는 목적지에 도착해야만 보상이 주어지기 때문에 대부분의 행동에 대해서는 이게 잘한 행동인지 못한 행동인지 알 수 없습니다. 행동을 여러 번 반복하다가 목적지(G)에 도착하든가 구멍에 빠져서 게임이 끝나서야 에이전트는 행동이 잘한 건지 알 수 있습니다.
Q 함수란?
Q 함수는 상태-행동 가치 함수라고도 불리며 상태와 행동을 입력했을 때 이에 대한 가치를 출력으로 주는 함수입니다.

Q에 내가 가진 상태(state)와 행동(action)을 주면 Q는 이런 상태에서 이런 행동을 하면 얼마큼의 보상을 받을 수 있는지 알려줍니다.
Q가 이를 알려준다면 에이전트는 어떤 정책(policy)를 취하면 될까요? 간단합니다. 최대 값인걸 찾으면 됩니다. 최대값을 주는 행동을 찾아 그 행동을 하면 됩니다. 이를 수식으로 표현하면 다음과 같습니다.
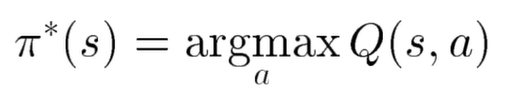
정책(policy)은 보통 π로 표현합니다. argmax는 Q(s,a)를 최대로 하는 action을 찾는다는 뜻입니다. (argmax 밑에 붙은 a가 action을 의미) π 옆에 붙은 *는 최적의 값임을 말하는 데 Q를 최대로 하는 action을 취하는 정책이 최적임을 의미합니다.
Q를 어떻게 만들까
Q만 알면 정책대로 액션을 취하면 됩니다. 문제는 Q를 찾는 것입니다. Q를 찾는 것을 Q를 학습한다라고도 합니다. Q를 어떻게 찾을 수 있을까요? Q를 찾으려면 믿고 시작하는 게 필요합니다. 현재에는 Q를 모르지만 미래에는 Q를 안다고 믿어야 합니다.
에이전트는 현재 s라는 상태이고 a라는 액션을 취합니다. 그러면 에이전트의 상태는 s'으로 변하게 됩니다. a라는 액션을 취했을 때 에이전트는 r이라는 보상을 받게 됩니다. s 상태에서 Q 값은 모르지만 s' 상태에서의 Q는 알고 있다고 가정하는 것입니다. 그리고 아래의 수식을 반복하여 Q를 학습합니다.
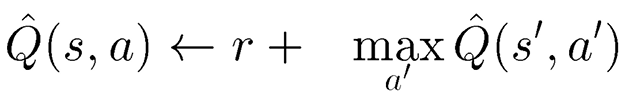
<-는 대입하는 걸 의미합니다. s 상태에서 a 액션을 취했을 때의 Q 값은 a 액션을 취했을 때의 보상 r + s' 상태에서 액션을 취했을 때 얻을 수 있는 최대 Q 값으로 얻는 것입니다.
과연 위의 방법으로 Q가 학습이 될까요? Frozen lake 문제로 Q가 어떻게 학습되는지 살펴보도록 하죠.

위에서 정의했던 Q 함수를 다음과 같이 테이블 형태로 나타내었습니다. 16개의 상태를 가지고 각 상태마다 4개의 액션(위, 아래, 왼쪽, 오른쪽 이동)을 가집니다. 처음에는 Q 값을 모르니 0으로 초기화되어 있습니다. 에이전트는 열심히 돌아다니면서 위의 수식을 통해 Q를 업데이트합니다. 처음에는 모든 Q 값이 0이니 랜덤 하게 이동을 하게 됩니다.

목적지에 도달하는 것 외에는 모든 보상이 0이고 모든 Q 값이 0이므로
위의 수식으로 Q를 업데이트해도 대부분의 경우 Q 값은 계속 0입니다. 그러다 Q가 업데이트되는 순간이 있습니다. 에이전트가 목적지에 도달하기 전 상태가 되면 Q 값은 업데이트됩니다. (아래 그림에서 빨간 동그라미) 목적지에 도달하면 보상 r = 1이므로 빨간색 동그라미 상태에서 오른쪽으로 가려는 액션을 취할려고 하면 Q 값은 1로 업데이트 됩니다.
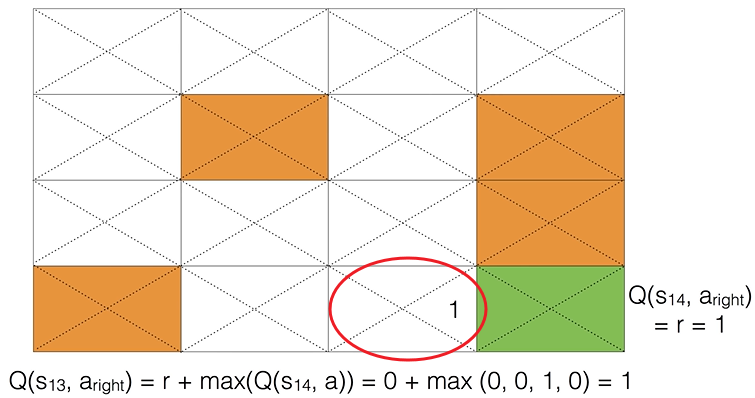
이렇게 하나의 업데이트가 이루어지고 나면 Q 값은 차례대로 업데이트돼서 다음과 같이 Q 값이 만들어질 수 있습니다.
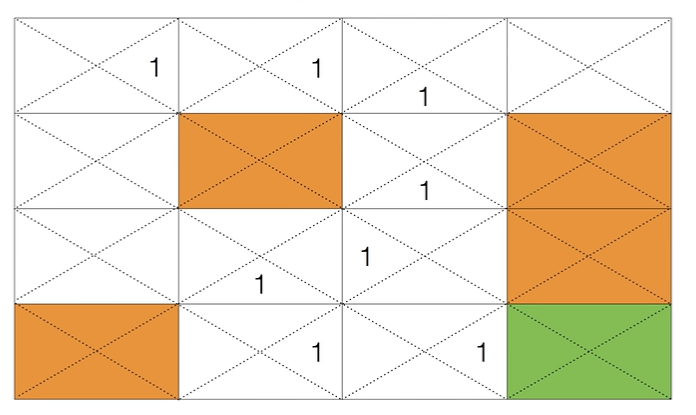
Q 값이 다음과 같이 만들어지면 에이전트는 optimal policy에 따라 목적지에 쉽게 도달할 수 있게 됩니다.
Dummy Q-learning 알고리즘
이를 알고리즘으로 표현하면 다음과 같이 표현할 수 있습니다.

import gym
from gym.envs.registration import register
import matplotlib.pyplot as plt
import numpy as np
import random
#MACROS
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
def rargmax(vector): # https://gist.github.com/stober/1943451
m = np.amax(vector)
indices = np.nonzero(vector == m)[0]
return random.choice(indices)
# Register FrozenLake with is_slippery False
register(
id='FrozenLake-v3',
entry_point="gym.envs.toy_text:FrozenLakeEnv",
kwargs={'map_name':'4x4','is_slippery':False}
)
env = gym.make("FrozenLake-v3")
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Set learning parameters
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = rargmax(Q[state, :])
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-table with new knowledge using learning rate
Q[state][action] = reward + np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList)/num_episodes))
print("Final Q-Table Values")
print("Left Down Right Up")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()frozen lake 문제 환경을 구축하려면 OpenAI gym을 이용해야 합니다. 해당 환경을 사용하는 법은 OpenAI GYM 간단한 사용법에서 확인하시면 됩니다.
11~14: ragrmax 함수는 random argmax의 줄임말입니다. Q 값이 모두 0으로 동일할 때는 랜덤 하게 선택하고 그렇지 않은 경우는 argmax를 합니다. Q 값이 가장 큰 액션을 고르게 합니다.
23: Q는 16 x 4 크기의 테이블로 0으로 초기화됩니다. gym 라이브러리로 env.observation_space.n으로 환경의 상태 개수, env.action_space.n으로 액션 개수를 불러올 수 있습니다.
27: rList는 해당 에피소드에서 목적지 도달 여부를 확인하기 위한 리스트입니다. reward가 1이면 목적지에 도달한 것이고 0이면 도달하지 못한 것입니다.
해당 프로그램을 실행하면 Sucess rate와 Q 값이 터미널에 출력됩니다.

대략 225 에피소드 이후부터는 거의 성공하는 걸 확인할 수 있습니다.

그 외 여러 기법들..
위의 dummy Q 러닝 알고리즘은 아직 보완할 부분이 있습니다. 그 중 하나로 이런 점을 들 수 있습니다. 현재의 알고리즘은 한 번 목적지까지 도달하여 테이블이 완성되면 다른 경로를 찾지 않고 계속 같은 경로로만 가게 됩니다. 그러나 많은 경우, 처음 완성된 경로 외에도 다른 경로로 갔을 때 더 큰 보상을 줄 수도 있고 혹은 지금 경로보다 더 빠른 경로가 있을 수도 있습니다. 이런 문제점을 개선하기 위한 방법이 Exploit & Exploration 방법을 사용합니다.
그 외에도 learning rate α을 사용해서 Q함수를 점진적으로 업데이트하는 방법도 있습니다.
*reference
단단한 강화학습
Qrash course: Reinforcement Learning 101 & Depp Q Networks in 10 Minutes
'Machine Learning > Reinforcement Learning' 카테고리의 다른 글
| OpenAI GYM 간단한 사용법 (feat. FrozenLake) (0) | 2021.11.09 |
|---|
