* 해당 자료는 김성훈 교수님의 모두를 위한 강화학습을 참고하여 작성하였습니다.
OpenAI GYM
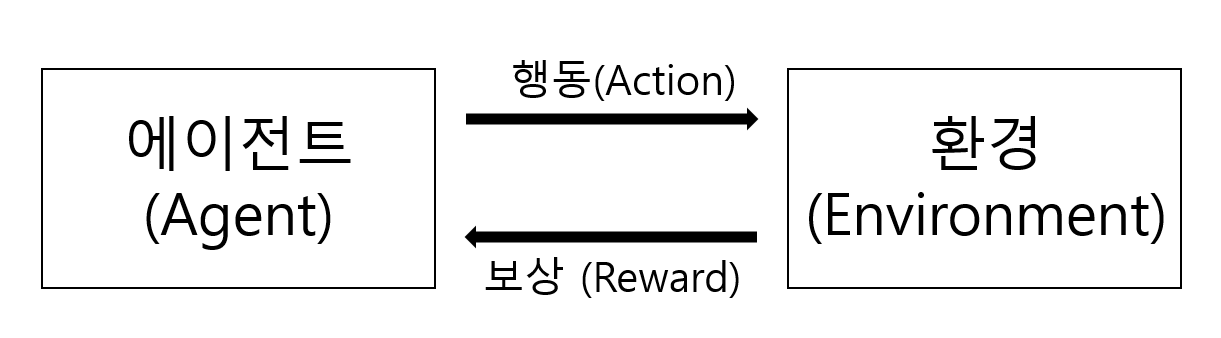
강화학습에는 에이전트와 환경이 있습니다. 에이전트는 어떤 행동을 하고 에이전트가 행동을 할 때마다 환경 속에서의 상태는 바뀌게 됩니다. 강화학습을 하려면 에이전트와 환경이 있어야 되는 데 이 때 환경을 만드는 일은 복잡하고 귀찮은 일입니다.
OpenAI GYM은 강화학습 환경을 만들어주는 프레임워크입니다. OpenAI GYM으로 강화학습 환경을 만들어 사용하면 환경을 구성하는 데 신경쓸 것 없이 주어진 환경에서 강화학습 알고리즘에 집중할 수 있습니다.
GYM은 다음 명령어로 설치할 수 있습니다.
pip install gym
FrozenLake
FrozenLake는 OpenAI GYM에서 제공하는 환경 중 하나입니다. 간단한 환경이기에 예시로 많이 사용됩니다.
아래 그림은 FrozenLake 예시입니다.

S는 시작점(Starting point). F는 얼은 면(Frozem surface). H는 구멍(Hole). G는 목표지점(goal).
시작 지점에서 구멍에 빠지지 않고 목표지점에 도착해야하는 게임이라고 생각하시면 됩니다.
에이전트와 환경과의 관계로 보면 다음과 같습니다.
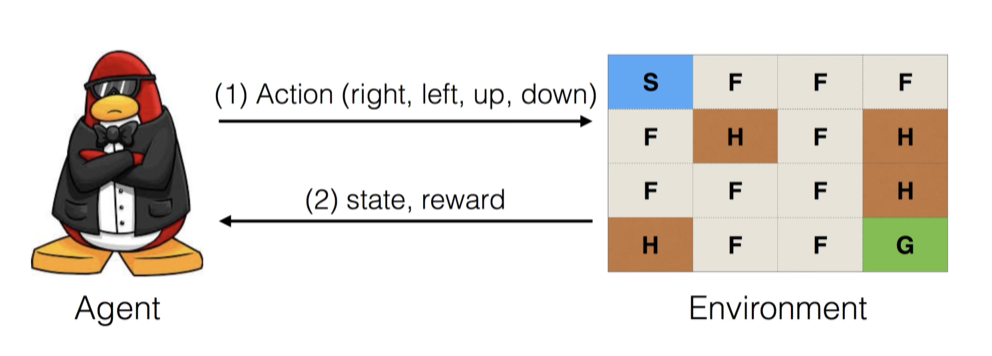
에이전트는 FrozenLake 안에서 상하좌우로 움직일 수 있습니다. 에이전트가 액션을 취하면 환경은 그에 맞는 상태나 보상을 주게됩니다.
비교적 간단한 환경이므로 해당 환경을 직접 만드는 게 어렵지 않다고 생각하실 수도 있는데 OpenAI GYM에서는 make 함수 하나로 환경을 만들 수 있습니다.
import gym
env = gym.make('FrozenLake-v1')
환경을 사용하기 전에 reset()을 해줘야 합니다. 현재 환경을 렌더링 하고 싶으면 render()를 사용합니다. 현재는 아직 목표지점을 가기 위한 알고리즘이 없으므로 랜덤 액션을 취하는 env.action_space.sample() 함수를 호출해봅니다.
import gym
env = gym.make('FrozenLake-v1')
env.reset()
for _ in range(100):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
window10 환경 FrozenLake 예시
지금은 Agent가 움직이는 알고리즘은 없습니다. 다만 환경이 어떻게 동작하는 지 살펴보기 위해 키보드 입력을 받아서 agent가 움직이도록 코드를 작성해봅니다.
w는 위로, s는 아래로, d는 오른쪽으로, a는 왼쪽으로 agent가 움직입니다.
import gym
from gym.envs.registration import register
import readchar
#MACROS
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
# Key mapping
arrow_keys = {
'w' : UP,
's' : DOWN,
'd' : RIGHT,
'a' : LEFT
}
# Register FrozenLake with is_slippery False
register(
id='FrozenLake-v3',
entry_point="gym.envs.toy_text:FrozenLakeEnv",
kwargs={'map_name':'4x4','is_slippery':False}
)
env = gym.make("FrozenLake-v3")
env.reset()
env.render()
while True:
# Choose an action from keyboard
key = readchar.readkey()
if key not in arrow_keys.keys():
print("Game aborted!")
break
action = arrow_keys[key]
print(arrow_keys[key])
state, reward, done, info = env.step(action)
env.render() # Show the board after action
print("State:", state, "Action", action, "Reward:", reward, "Info:", info)
if done:
print("Finished with reward", reward)
break
*reference
김성훈 교수님의 모두를 위한 강화학습
'Machine Learning > Reinforcement Learning' 카테고리의 다른 글
| [강화학습] Q 러닝 이해하기 (1) | 2022.01.09 |
|---|
